 Là ça y est, Google est vraiment vexé.
Là ça y est, Google est vraiment vexé.
Matt Cutts et son équipe responsable de combattre le spam ont pris dans les dents les critiques récentes à propos de la domination du moteur de recherche par les spammeurs, référenceurs et webmarketeurs.
Sauf que la cible de choix se tourne encore et toujours vers les spammeurs, laissant croître les saloperies de contenu qui ne valent pas un clou.
Le discours sur le spam et Google n’est pas neuf. Par contre, 2011 a l’air d’avoir affirmé le constat d’incapacité latente pour le moteur de combattre ce qu’il considère comme de la pollution.
Pan dans les dents
Quand des ténors du référencement tels que SEOMoz évoquent ce constat, Matt Cutts fait « gloup », lorsqu’un blog majeur comme ReadWriteWeb roucoule, ça hérisse les cheveux de toute l’équipe antispam, mais quand c’est carrément le Washington Post qui sonne la charge, alors ça fait vraiment tâche sur toute l’entreprise Google. Avec le fondateur historique, Larry Page, qui prend les rênes de CEO, j’ose penser qu’il y a eu remontée de bretelles. En réponse, Matt Cutts nous sert un post sur le blog officiel, puis enchaîne avec un update d’algorithme.
Plus près de nous, l’insatiable Sylvain nous décline les maux attribués au référenceur ; ce qui m’a inspiré d’extrapoler sur mon commentaire au travers de ce billet.
A Lire également le dossier sur Webrankinfo : les changements de l’algorithme Google depuis 1 an.
Black Hat SEO et AFP Rewriting, même combat
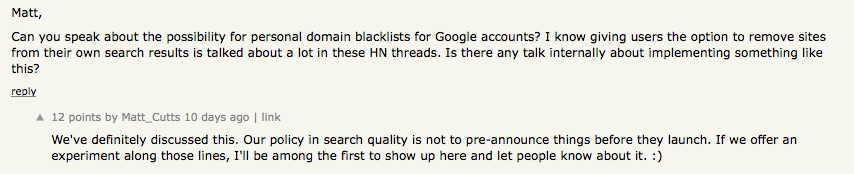
En parallèle à ces affronts médiatiques, le moteur Blekko fait parler de lui. La mise en évidence de la « propreté » des résultats de recherche comparés à ceux de Google fait obligatoirement grincer des dents du côté de Mountain View. On peut en lire la trace évidente dans cette discussion sur Hacker News où Matt Cutts évoque la possibilité d’avoir un Blekko Like sur Google.
Pour couronner le tout, l’entrée en Bourse de Demand Media, société éditrices de fermes de contenu, évoque des sourires narquois sur la possibilité de générer des fortunes en publiant du contenu bas de gamme.
C’est ce dernier point qui me préoccupe car le dernier update vise apparemment le scraping de base (Note : je n’ai pas encore ausculté cet update en profondeur), laissant la place au contenu de merde qui est toujours aussi bien valorisé par le moteur.
D’après les statistiques internes à Google, le spam serait en recul… sauf qu’on n’a pas vu ses données.
Le problème est que du petit bout de notre lorgnette, rien n’a changé.
Matt Cutts peut bien faire des effets d’annonce avec un update lâché à la hâte, ça n’enlèvera pas que les paramètres « off page » seront toujours quasiment impossibles à combattre.
Je m’explique…
Depuis toujours, Google a focalisé son combat sur le contenu caché, généré automatiquement, etc. Ce sont des éléments « on page » sur lesquels les progrès sont sensibles ; même si le volume permet encore d’obtenir des résultats. La stratégie reste identique, mais la méthodologie a sensiblement évolué.
Avant, il suffisait, par exemple, de mélanger des flux RSS (Yahoo! Pipes est fabuleux pour faire cela) ou scraper de manière basique 2 ou 3 pages pour fabriquer un contenu soi-disant unique.
En plus du scraping, le spinning consiste à prendre un texte et mélanger les phrases. Aujourd’hui, je dissocie cette notion de spinning avec le morphing qui consiste à introduire des variables sur certains mots clés (voir aperçu ci-dessous extrait du mode d’emploi de Xrumer).

Une autre méthodologie intéressante tend à traduire automatiquement des textes. Sauf que le résultat est toujours une bouillie infâme de mots si on ne prend pas la peine de travailler avec des dictionnaires customisés et plus.
Il y a juste une parade qui consiste à corriger la traduction automatique ; c’est bien moins couteux que créer du contenu à partir de 0 ; même s’il s’agit de paraphrase basique qu’on appellera AFP Rewriting en hommage aux innombrables sites d’infos qui se contentent de réécrire à la hâte des dépêches AFP ou autre.
Apparemment, le dernier update vise surtout les scrapers qui récupèrent du contenu sur diverses sources pour générer une soupe infâme. Franchement, ça ne n’impressionne pas de viser ce type de contenu en 2011. Surtout qu’il y a un paquet de sites qui sont pris dans la tourmente sans être concerné par cette technique.
Tout ça pour dire que les techniques visant à fourguer du contenu dans les moteurs évoluent. Combattre le spam de base n’est pas le problème ; c’est le contenu de basse qualité qui doit être la cible.
Le seul hic est que la vaste majorité du Web est de basse qualité.
J’ai trituré en long, en large et en travers des textes à base de morphing automatique ou de AFP Rewriting (paraphrase basique) effectuée à la main. Tous les résultats de Latent Semantic Analysis que j’ai tenté sont unanimes ; il n’y a pas ou très peu de différence entre le contenu généré automatiquement de manière subtile ou le contenu généré à la main de manière basique. Parfois, le contenu automatique obtient un meilleur score que le contenu rédigé à la main.
Ainsi, il faut voir que Google n’est pas sorti d’affaire s’il veut vraiment s’attaquer aux fermes de contenu et équivalent en termes de qualité rédactionnelle. Pour autant, le Web n’a pas vocation de contenir uniquement des écrits destinés à gagner le prix Pulitzer. A partir du moment où Google n’est pas un moteur sémantique, il ne comprend pas ce qu’il lit, la tâche n’est pas aisée pour la batterie d’algorithme et l’armée d’ingénieurs superstars. A priori, des sites appartenant au réseau Demand Media, comme ehow.com, pourraient servir d’exemple, mais l’AFP Rewriting ou le MFA (MadeForAdsense) est loin d’avoir rejoint le caveau.
Bon, reste aussi à évoquer la problématique du contenu dupliqué.
De ce côté, Google a fait d’énormes progrès pour gérer les URLs dupliquées sur un même site. Auparavant, on pouvait faire tomber une page simplement en générant des URLs dupliquées fantômes vers lesquelles des backlinks iront pointer.
Si j’en crois la dernière update, le problème du contenu partiellement dupliqué entre différents sites est en ligne de mire. Sans même parler de Black Hat SEO, c’est toujours inquiétant de voir pointer un agrégateur de flux RSS avant sa propre URL.
Jusqu’à présent, on pouvait toujours récupérer un texte déjà publié en ligne et faire sauter l’antériorité ; du moment qu’il y avait assez de backlinks pointant vers la nouvelle source. A voir si cela va toujours être possible.
C’est justement une transition parfaite pour mon point suivant qui est pour moi celui où Google reste coincé.
La loi du backlink
Un dicton du SEO dit « donne moi un titre et des backlinks avec anchor text adéquat et je te positionne une page sans contenu ».
Le pouvoir du lien entrant n’est pas à démentir. Après la balise TITLE, c’est pour moi le deuxième élément le plus important de tous les facteurs influents le référencement.
Les liens sont le sang du Web et Google n’existerait pas sans eux puisque c’est grâce au maillage entre les sites qu’il peut indexer le Web. Le concept même du PageRank est basé sur le transfert de popularité entre les pages qui sont liées.
Bref, le lien est vital, fondamental, indispensable.
Sauf que je ne suis pas forcément responsable des liens qui pointent vers mon site. C’est là le point crucial qui met Google dans une impasse. A partir du moment où il pénalisera un site à cause d’un profil de liens dégueulasse, nous ne ferons plus de référencement, mais simplement du déréférencement des concurrents. Si le site est irréprochable « on page » et donnons lui un profil de liens classique pour démarrer, comment Google peut le pénaliser s’il attire soudainement un afflux massif de liens avec une empreinte nette de Black Hat SEO ?
Le problème est de faire du crade « on page » et « off page » , mais si vous donnez de l’amour à votre site comme dit mon cher ami Tiger, vous avez énormément de latitude « off page ».
Mettons que vous souhaitez vous positionner sur un mot clef concurrentiel. Vous fabriquez vos pages pertinentes et tout. Après, vous entamez le travail de besogneux du netlinking à la main. Avec tout ça, vous arrivez en fond de première page après quelques semaines de travail. Par-dessus cette couche « propre », mettez les gaz en linking automatique avec Xrumer ou équivalent. De la sorte, il y a de fortes probabilités que vous arriviez à vos objectifs.
Le dernier update évoque ce paramètre en impliquant l’empreinte donnée par les commentaires typiquement classés comme du spam. Oui mais l’attribut nofollow n’était pas conçu pour éradiquer ce problème à la base ? C’est vrai, mais on voit bien que ce pétard mouillé est devenue une véritable farce ou plutôt une vilaine verrue. Enfin bon, lorsqu’on voit le potentiel des logiciels de linking automatique, viser l’empreinte de commentaires spammy donne l’impression d’une 2CV qui fait la course contre une Formule1.
Alors, Google coincé ?
Pour moi, le constat est sans appel par rapport à l’archi domination des spammeurs, référenceurs et webmarketeurs sur Google ; sans avoir des notions de référencement, dur de se faire une place au soleil.
Je vois mal le moteur effectuer un virage à 90% pour populariser autre chose que l’existant. Il pourra continuer de faire du fine tuning comme avec le dernier update, touchant 1 ou 2% des résultats de recherche au grand maximum, mais difficile de changer une équipe qui gagne. Sur le plan global, on ne peut nier que Google gagne encore et toujours. Les power users trouvent toujours à redire sur la qualité des résultats de recherche, mais l’internaute lambda est ravi puisqu’il trouve réponse à sa requête. D’ailleurs, la plupart du temps, il ne sait même pas que le site consulté est une ferme de contenu ou un racoleur commercial.
Le combat de Google peut être en apparence contre le vilain spam, mais les Black Hat SEO savent évoluer plus rapidement que les mises à jour d’algorithme. C’est comme cela depuis le début et rien ne changera à ce niveau.
Pour ce qui est du « on page », il faut devenir plus sophistiqué, mais rien de difficile à servir du contenu passable pour assouvir le glouton moteur. En ce qui concerne le « off page », j’attends de voir comment Google peut s’en sortir. Dévaluer la pondération du backlink semble la solution évidente, mais c’est l’algorithme de base (Google fonctionne avec un algorithme par couches) qui est touché. Ce dernier date de 1996 avec une refonte en 2001 ; ça serait un gros chantier pour revoir entièrement le système de pondération.
Dans mon titre, je suggère que le spam n’est pas le problème car les Black Hat SEO ou autre spammeurs ont déjà évolué dans la génération de contenu. Les indices récents de lutte donnés par Google s’attaquent encore à de vieux démons qui sont dépassés par l’arsenal d’aujourd’hui pour ceux qui évoluent du côté obscur de la Force. Le contenu de qualité médiocre est beaucoup plus difficile à contrer. A ce niveau, Google est loin du compte… très très loin…
Bref, on verra bien, mais en attendant je ne me fais pas la moindre illusion sur le vain combat de Google contre le spam et surtout contre le contenu de basse qualité.