![]()
Cela faisait un moment que j’avais entamé la traduction (autorisée) de l’article suivant. Il était oublié au fond d’un répertoire, puis je suis retombé par hasard sur l’article original de SEOmoz rédigé par Rand Fishkin et Ben Hendrickson.
Après une nouvelle lecture, j’ai pensé qu’il serait vraiment intéressant de terminer la traduction pour partager cette analyse passionnante avec ceux qui sont en délicatesse avec la langue de Shakespeare.
Le but de cette analyse est de comprendre un peu mieux l’algorithme de Google en effectuant une corrélation de données sur la base de l’index Linkscape.
Corrélation de données
Linkscape est l’index Web de SEOmoz. En plus du travail habituel sur les statistiques, nous effectuons des recherches poussées qui sont partagées dans cet article. Cependant, la lecture requiert de l’attention car la corrélation de données ne donne pas forcément toutes les réponses. Il n’en demeure pas moins que c’est extrêmement intéressant, donnant une vue de l’intérieur grâce à la modélisation des classements; tout en sachant qu’il ne faut pas simplement regarder les graphes, mais bien lire le commentaire associé. Donc, faites attention à la lecture des données brutes qui peuvent être sujettes à une mauvaise interprétation.
Quelques stats Linkscape (au 22/09/09)
- Date de sortie : 6 octobre 2009
- Domaines : 57 millions
- Sous-domaines : 215 millions
- URLs : 40,5 milliards
- Liens : 456 milliards
- Attributs de lien :
- Liens nofollow internes : 7 milliards (1,51% du total)
- Liens nofollow externes : 2,8 milliards (0,60% du total)
- Liens nofollow au total : 9,7 milliards (2,11% du total)
- URLs en 301 : 384 millions (0,08% du total)
- URLs en 302 : 3 milliards (0,59% du total)
- URLs employant rel= «canonical» 52 millions (0,01% du total)
- Corrélation moyenne entre PageRank et mozRank
- Erreur absolue moyenne : 0,54
- Corrélation moyenne entre mozRank du domaine (DmR) et PageRank de la homepage
- Erreur absolue moyenne : 0,37
Maintenant, entrons dans la recherche autour de la corrélation des données pour savoir comment utiliser Linkscape pour obtenir des statistiques intéressantes. Les premiers graphes utilisent la corrélation brute et pas seulement la relation entre les classements et les paramètres individuels. Encore une fois, il faut bien lire les descriptions et surtout ne pas faire de conclusions hâtives. Il ne faut pas croire qu’on peut forcément obtenir un meilleur classement en suivant les recommandations. Le but est de montrer quels paramètres sont appliqués aux pages qui sont positionnées parmi les meilleures positions des résultats de recherche.
Comprendre les graphes
- Mean Index By Value (index moyen par valeur) : c’est utilisé pour l’axe y de plusieurs graphes. Au lieu de faire la moyenne des valeurs brutes, nous effectuons le calcul sur son index relatif dans les résultats de recherche – si ordonnés par cette valeur. Prenons 3 résultats de recherche où la page en première position est la quatrième en terme de liens, la deuxième est la première pour les backlinks, puis la troisième est en dixième position pour les liens. L’index moyen par nombre de liens pour la première position sera (4+1+10)/3=5.
- Mean Count Numbers (moyenne des nombres) : ces nombres apparaissent sur l’axe y du premier graphe, montrant la moyenne du nombre de liens.
- Position : c’est utilisé sur certains axes x. Pour les graphes concernés, spécifiques à la position organique dans Google.com, les résultats de recherche non traditionnels sont exclus (local, vidéo, news, images, etc.).
- Error Bars (Barres d’erreur) : ces barres qui relient les courbes dans nos graphes montrent l’intervalle entre deux éléments différents. Sur certains graphes, elles montrent les 95% des intervalles de la moyenne potentielle si nous avions une infinité de données à traiter.
Les backlinks sont-ils en corrélation adéquate avec le positionnement ?
Une logique récurrente dans le référencement prétend que le nombre de liens qui pointent vers un résultat permet une bonne prédiction du positionnement. Cependant, on remarque que Yahoo! Site Explorer (et même Google dans ses Webmaster Tools) inclut un grand nombre de liens inutiles (nofollow, format exotique, internes, etc.), tandis qu’il exclut des éléments intéressants (comme les redirections 301).
En utilisant les données Linkscape, nous pouvons éliminer ce bruit afin d’extraire seulement les liens qualifiés et les 301.
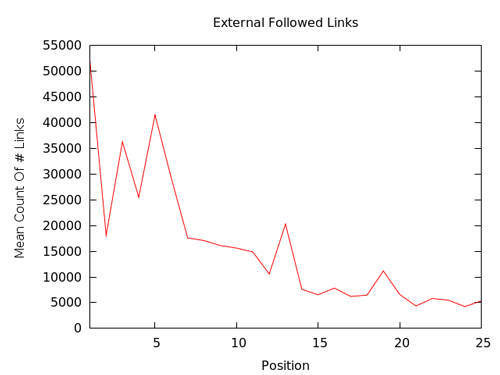
Ce premier graphe suggère qu’une corrélation existe entre nombre de liens et positionnement. Sauf que les pics sont frustrants. Au travers d’une analyse plus profonde, nous avons établi qu’il était évidemment causé par un déséquilibre de liens parmi certains résultats. Du coup, il s’est avéré pertinent de produire le graphe suivant :
Ici, nous pouvons voir ce qui pourrait se passer si nous manipulions les résultats par nombre de liens. Dans ce cas, chaque paquet de résultats ont été assigné un chiffre (1, 2, 3, etc.) qui correspond à la quantité de liens en comparaison avec les autres pages (la page avec le plus de liens est assignée le « 1 », la deuxième qui reçoit le plus de liens porte le « 2 », etc.). On voit que la courbe est devenue régulière, mais nous pouvons assurer de sa précision.
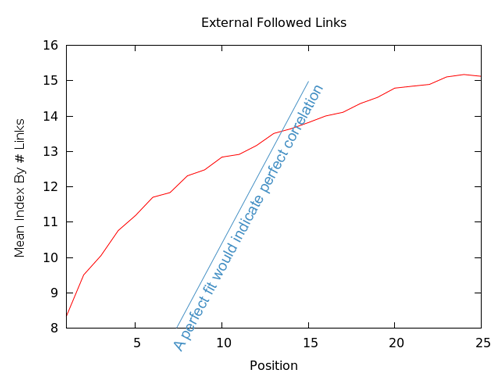
Les barres sur la courbe ci-dessous montre l’intervalle permise pour estimer la ligne médiane.
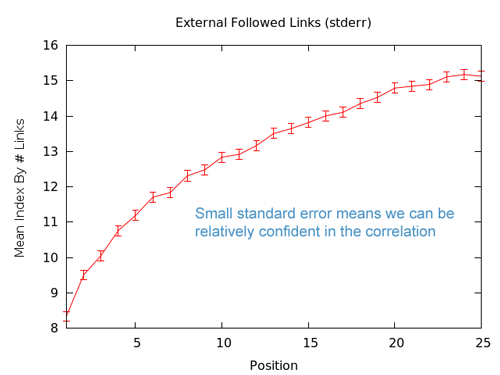
La corrélation est forte, suggérant que le nombre de liens externes est important. Le standard relevé pour l’erreur est si bas que nous sommes confiants à propos de la véracité de cette analyse. Clairement, les liens sont très importants, mais ils ne représentent pas la totalité de la solution. Amasser le plus de liens possible est un excellent objectif, mais cela ne peut pas être votre seul but.
Le dernier morceau à observer pour cette partie concerne la déviation standard. Cela démontre la latitude de variation d’une page par rapport aux moyennes.
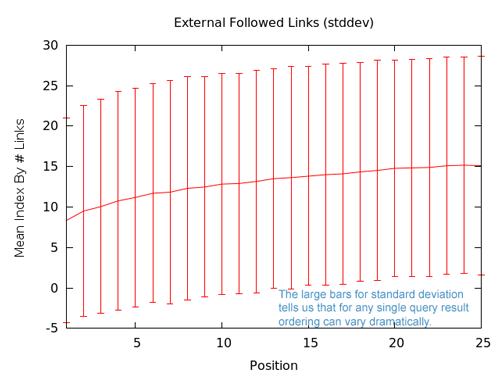
Ce graphe nous montre que la variation pour un paquet individuel de résultats peut être très large. Acquérir plus de liens n’est pas forcément un moyen infaillible. La déviation standard est éloignée de la ligne médiane (1,97). Au niveau global, il importe de prendre en compte le nombre de liens externes qui sont correctement suivis, mais nous allons développer nos modèles et élargir notre champ de réflexion pour d’obtenir des informations actionnables au niveau granulaire.
Une seule mesure peut-elle prédire le positionnement ?
Franchement, ça serait excellent…
Nous avons regardé des indices comme le PageRank, le nombre de liens dans Yahoo! Site Explorer, Alexa Rank, etc. Pour être clair, ces indices sont aussi fiables que piocher au hasard. Le score du PageRank de Google était approximativement 16% plus performant (donnée datée de février 2009) qu’une prédiction basée sur le hasard pur pour déterminer le positionnement d’une page Web (N+10 ou la page positionné N°1 contre la page 2). Le PageRank était également 5% meilleur que le hasard pour prédire le positionnement (N+1 ou la position 1 contre position 2).
Le graphique ci-dessous montre des corrélations pour un certain nombre d’indices liés au référencement.
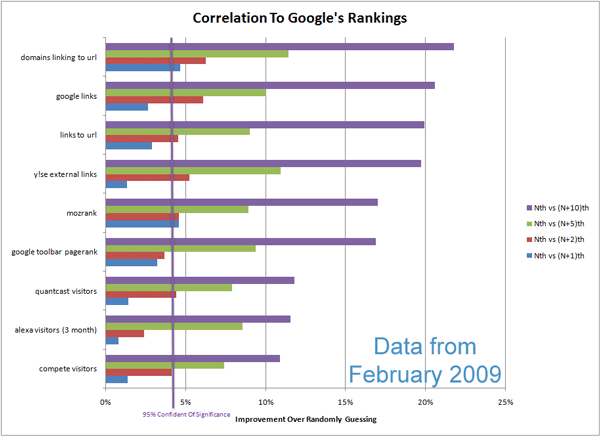
Nick, Ben et Chas ont travaillé dur afin d’améliorer la valeur et la qualité de l’index Linkscape, ainsi que l’utilité des mesures.
Le graphe suivant montre nos progrès.
Les corrélations du graphe ci-dessus sont 35-50% plus satisfaisantes que les résultats piochés au hasard (il ne s’agit pas d’une comparaison 1 pour 1 avec les nombres ci-dessus – cela viendra dans un prochain post). L’observation de ce graphe suggère que le mozRank externe (représentant la quantité de « link juice » vers un page depuis les liens externes) et les liens externes suivis correspondent bien au positionnement actuel, apportant des éléments d’information intéressants pour les chasseurs de backlinks. Cette ligne de corrélation peut suggérer, dans un scénario classique du positionnement, l’importance de l’apport de liens émanant de pages à fort mozRank/PageRank qui contiennent peu de liens externes (ainsi les liens passent plus de « link juice »), ainsi qu’une grande quantité brute de liens externes suivis. De plus, ce graphe supporte l’idée que l’apport de liens depuis un domaine unique est pertinent.
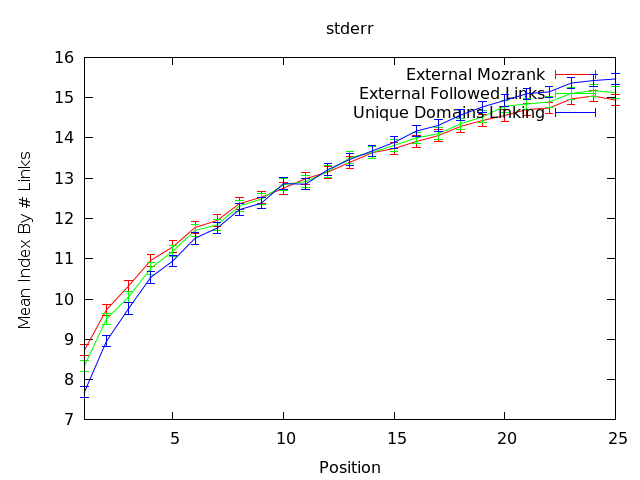
La partie frustrante à propos de ces donnés est que ça ne raconte pas l’ensemble de l’histoire, ni que ça soit directement actionnable pour une requête spécifique. Comme vous pouvez voir ci-dessous, la déviation standard des nombres montre que pour n’importe quelle recherche, l’étendu varie drastiquement.
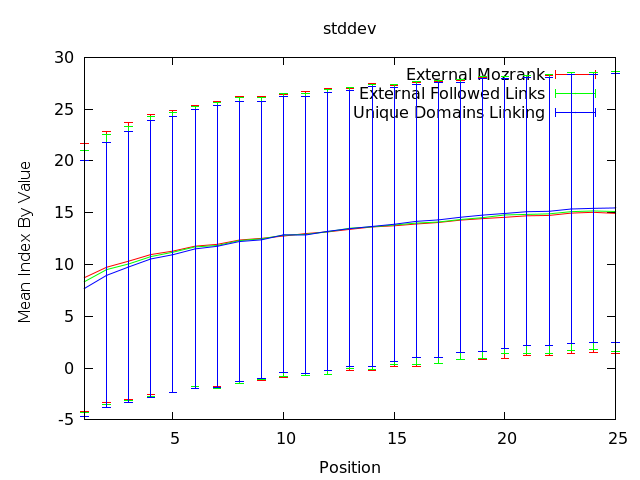
Lorsque nous observons cet effet, exactement comme dans le cas ci-dessus, l’application pour un travail de référencement d’un projet client, dont l’objectif est d’obtenir un positionnement spécifique, n’est pas clair. Employer ces mesures comme KPI et moyens d’évaluer les liens potentiels est probablement utile. Construire des analyses de concurrence avec ces points de données sera certainement plus efficace qu’utiliser des mesures extérieures, mais cela ne dit pas « fais ceci pour mieux te positionner, » tout comme ce n’est pas le « Saint Graal » que nous pourchassons.
Comment les facteurs « On Page » coïncident avec le positionnement ?
Pour l’instant, nous avons peu évalué les facteurs « On Page » et leur corrélation avec le positionnement. C’est ce que nous allons voir maintenant.
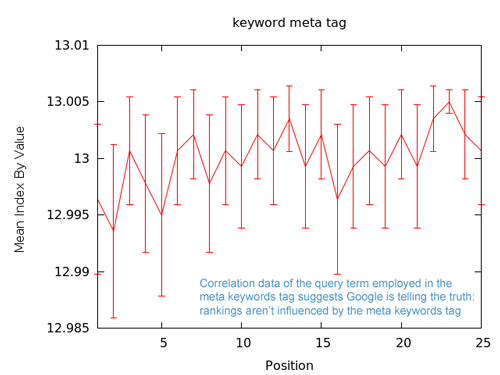
Google a récemment annoncé que la meta keywords était ignorée. Ces données montrent une courbe très irrégulière et des barres d’erreurs dans la limite du 13, supportant cette affirmation. Employer la requête/phrase dans la meta keywords est un des signaux les moins significatifs que nous avons étudié.
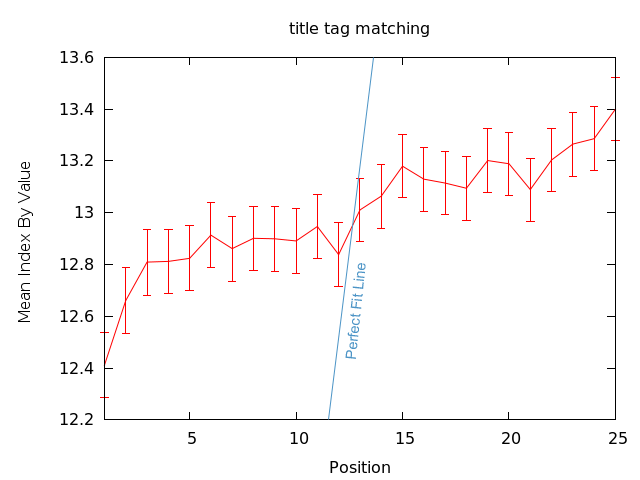
La balise Title qui contient le terme de la requête semble avoir une réelle corrélation avec le classement. Ils ne sont pas en parfaite corrélation, mais ce graphe nous montre que Google a une claire préférence, en moyenne, pour les pages qui emploient le terme de la requête dans la balise Title.
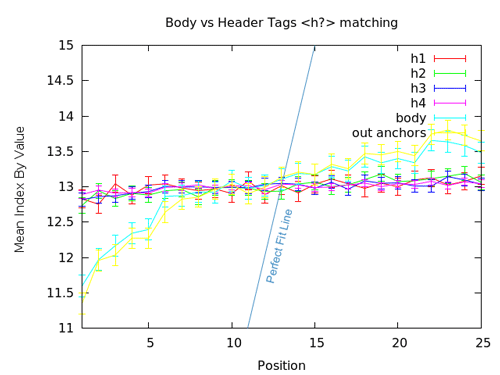
Nous avions examiné auparavant les balises d’en-têtes H1/H2/Hx pour arriver à la conclusion qu’elles avaient un impact faible sur le positionnement. Ce graphe suggère que c’est toujours le cas. Il y a une corrélation plus grande lorsque les termes sont utilisés dans d’autres zones «on page» du body ou dans l’ancre des liens (internes ou externes). Bien que le graphe montre une courbe horizontale, suggérant que les en-têtes H1 à H4 n’ont pas trop de bénéfice à l’utilisation, ce n’est pas aussi vilain que l’effet hasardeux observé avec la meta «keywords» (les courbes démarrent en-dessous de 13 et se terminent juste au-dessus). En tout cas, la corrélation positive est basse avec la ligne horizontale qui se tient entre les barres d’erreur.
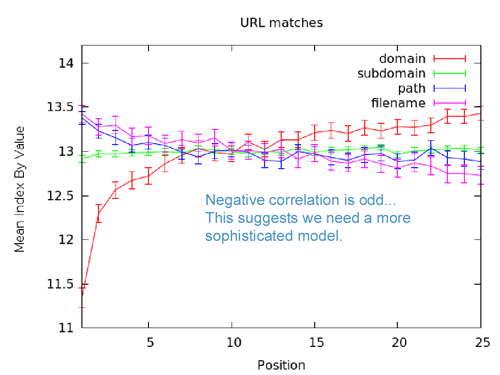
Le graphe est l’illustration la plus claire du fait qu’il faille construire des systèmes plus avancés qu’une simple et directe corrélation. Selon ce graphe, l’utilisation du terme de recherche dans le nom de fichier ou chemin d’URL est légèrement négatif en corrélation avec un bon classement. Le sous-domaine apparaît largement inutile, tandis que le domaine racine à une forte corrélation. Bien que toutes les courbes (sauf le domaine racine) soient sur une bande étroite de l’axe x, les bonnes pratiques du référencement nous dictent d’utiliser les mots clés dans ces éléments. Du coup, lorsque nous analysons ce graphe, il convient d’émettre quelques hypothèses. Par exemple, les termes de recherche de l’URL seraient éliminés lorsque ils apparaissent dans le domaine racine et ailleurs dans l’URL. Les moteurs de recherche peuvent voir ceux qui répètent les termes du domaine racine dans l’URL comme des pratiquants du « keyword stuffing ». Cela peut aussi impliquer que la corrélation brute perçoit un grand nombre de pages qui optimisent moins l’URL, mais qui sont performantes grâce à d’autres facteurs (liens, autorité, etc.). C’est aussi vrai que la plupart des sites qui emploient le mot clef dans l’URL ne l’utilisent pas forcément dans le domaine racine. Du coup, le négatif de l’un peut être mélangé au positif de l’autre pour tenter d’y voir plus clair.
Cet exemple est la parfaite illustration des problèmes d’interprétation sur la corrélation de données brutes, nécessitant une modélisation toujours plus sophistiquée.
Pouvons-nous construire une modélisation utilisable du positionnement?
Nous avons besoin d’un modèle qui imite Google du mieux possible pour obtenir une représentation de la valeur potentielle pour les actions de référencement. Sauf que ce n’est pas facile car Google possède plus de 200 paramètres dans son algorithme de classement des pages Web. Bien que nous possédons de nombreux points d’analyse, il n’en demeure pas moins que c’est un challenge complexe.
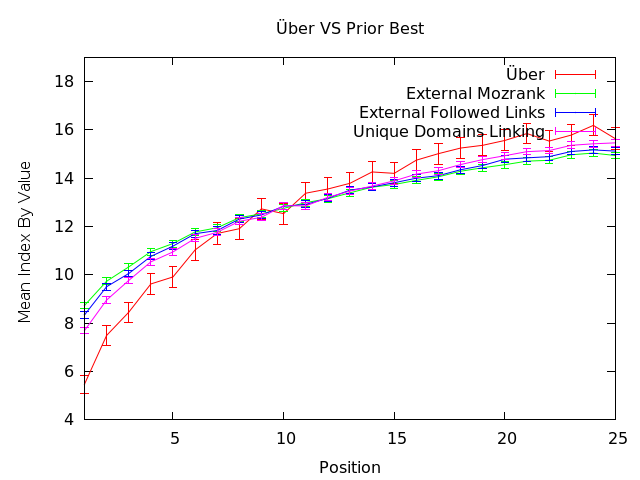
La courbe «Über» en rouge dans le graphe ci-dessus est construite en prenant tous les points d’analyse que nous possédons. Les données sont moulinées pour établir une corrélation avec les résultats de recherche. La courbe rouge fait clairement apparaître que notre modèle est le plus efficace pour prédire le classement. En plus, la courbe est carrément excellente pour le Top 10 des résultats de recherche.
Cette modélisation peut aussi s’affiner pour obtenir un impact à propos de l’utilisation du mot clef dans une zone spécifique.
Regardons comme exemple la corrélation négative des mots clés dans l’URL.
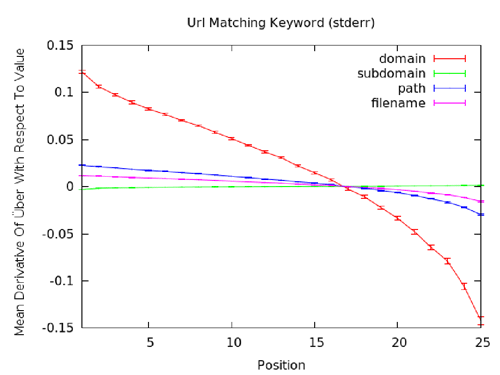
Encore une fois, le graphe montre clairement l’inefficacité latente des mots clés dans le sous-domaine, mais que c’est extrêmement efficace dans le domaine racine. Sinon, les courbes peuvent suggérer un faible effet positif tout en observant une descente en dessous du 0 de l’axe x pour les positions 20-25, indiquant que l’utilisation du mot clef peut aussi avoir un effet négatif. Ainsi, l’utilisation du mot clef au sein de multiples endroits peut être néfaste; ce qui dirait à certains qu’une utilisation moins agressive des mots clés serait bénéfique.
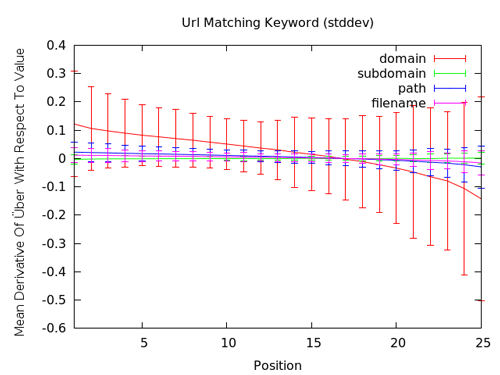
Dans ce graphe, les barres d’erreurs de déviation standard sont mises en évidence. Ainsi, nous pouvons dire que l’utilisation des mots clés dans l’URL n’a pas d’impact négatif pour les meilleurs résultats, tandis que ce constat est moins serein pour la dernière portion de résultats.
Tournons notre attention vers ces satanés Hx encore une fois pour voir si notre modélisation a d’autres choses à dire.
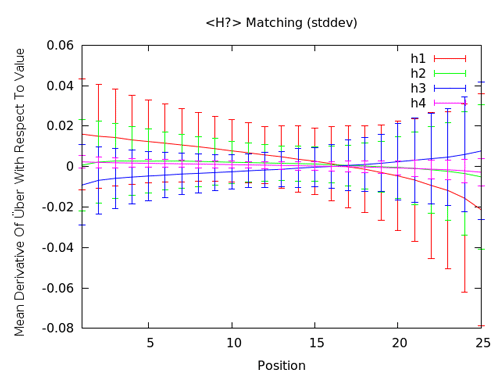
Nous obtenons des résultats similaires qui perçoivent les tags H1-H4 comme peu intéressants pour y placer des mots clés. Les Hx semblent aider un peu, mais peuvent aussi avoir un léger impact négatif pour la dernière portion des résultats. Cette analyse est une évidence plutôt efficace pour déclarer que les tags Hx n’ont pas une grosse importance pour le référencement (même en prenant en compte les barres d’erreur). Evidemment, il faut continuer d’utiliser les en-têtes, mais ce ne sont pas les endroits les plus stratégiques à incorporer à propos de l’optimisation pour le référencement.
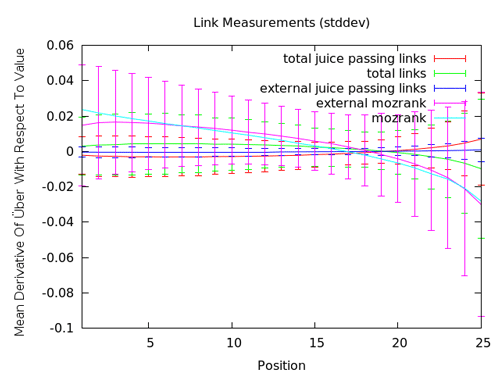
Notre mesure pour les liens a aussi été l’objet d’améliorations qui donne un constat plus nuancé. Vous pouvez voir ci-dessus que notre mozRank amélioré apparaît plus important pour les premiers résultats de recherche; tout en observant que le nombre brut de liens n’a pas une grande valeur. Plus profond dans les résultats, certaines pages semblent utiliser à outrance l’acquisition de liens et du mozRank – probablement à cause de liens qui proviennent de sites à faible autorité ou même spammy. Ce graphe ne contient pas un grand nombre de données actionnables, mais cela confirme plutôt bien ce qu’on sait du référencement (ex: peu de bons liens est mieux que beaucoup de mauvais liens).
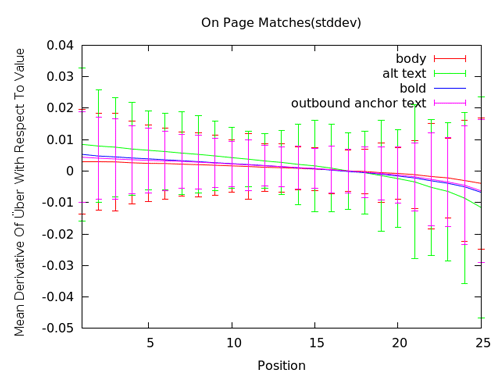
Ce dernier graphe montre quelques données intéressantes de nos tests sur les éléments «on page». Le gros paramètre aperçu concerne l’utilisation d’images avec un attribut «alt» adéquat incorporant les mots clés. La ligne verte est une des plus fortes corrélations pour l’utilisation «on page» des mots clés. Mettre les mots clés en gras, dans le corpus et même dans les ancres a le même type d’impact positif étudié précédemment, ainsi qu’un léger impact négatif dans la zone 20-25.
Conclusions
Je sais que cela représente beaucoup de données à ingurgiter, mais il est aussi très important de comprendre que la crédibilité du travail de référencement passe aussi par l’appui sur ce type d’analyse. SEOmoz n’est certainement pas la seule compagnie à travailler de la sorte (quoi que certainement la seule à rendre les résultats publics). Tout cela peut apporter des supports intéressants pour des projets clients ou en interne avec des données qui montrent l’importance et la valeur prévue pour les changements effectués en tant que référenceur. Nombreux sont ceux qui critiquent le métier parce que l’expertise se base énormément sur l’intuition et le bon sens. Avec ces analyses, nous pouvons recentrer le débat. Nous ne prétendons pas que ces données sont infaillibles, mais il s’agit certainement d’un excellent point supplémentaire à ajouter dans l’équation.
Les éléments suggérés par l’analyse, dont nous sommes confiants de la pertinence :
- Les liens sont importants, mais les données trop basiques peuvent être trompeuses. Il faut établir des analyses sophistiquées sur les liens.
- Il n’y a pas une donnée en particulier qui peut prédire le positionnement.
- H1 (et H2 à H4) ne sont probablement pas des bons endroits pour capitaliser sur des mots clés
- L’attribut «alt» des images est un endroit privilégié pour mettre des mots clés
- Le keyword stuffing peut vous retenir au-delà des 15 premiers résultats.
- En faire trop avec des liens de mauvaise qualité peut avoir un impact négatif.
=> Une autre étude à consulter sur les paramètres influents des backlinks.